
注:
本文采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。
Linux的network bridge和network namespace是两个非常重要的概念,它们是理解Kubernetes网络工作原理的基础。本文,我们将通过对Docker网络环境的模拟,进一步理解network namespace和veth pair的工作原理。

在Kubernetes网络篇——从docker0开始一文里,我们已经初步讨论了Linux网络名字空间(network namespace)和网桥(network bridge)的基本概念,并通过对Docker的默认网桥docker0的分析,明白了Docker是如何利用docker0和veth pair,实现容器和外界的网络通信的。
接下来,我们将手工创建network namespace和相应的网桥来模拟Docker的行为,以进一步理解Docker在容器启动时网络设置的工作原理。
创建网桥
利用brctl命令,我们可以创建自己的网桥:
$ brctl addbr lab-br0
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024277d8e553 no vethe657f66
veth617de44
lab-br0 8000.000000000000 no
并为它指定IP地址:
$ ifconfig lab-br0 10.15.10.1 netmask 255.255.255.0
$ ifconfig lab-br0
lab-br0 Link encap:Ethernet HWaddr 36:5F:BE:DC:14:14
inet addr:10.15.10.1 Bcast:10.15.10.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
这里,我们为新建的lab-br0网桥指定的IP地址为10.15.10.1。它位于10.15.10.0网段内,子网掩码为255.255.255.0。

创建network namespace
然后,我们再创建一个network namespace,比如叫lab-ns0,用来模拟一个容器:
$ ip netns add lab-ns0
$ ip netns list
lab-ns0

创建并配置veth pair
接下来,再为lab-ns0指定一对虚拟以太网接口,分别起名veth0和veth1:
$ ip link add veth0 type veth peer name veth1
$ ip link list
... ...
10: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 62:a1:e7:5c:20:29 brd ff:ff:ff:ff:ff:ff
11: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 22:ad:bb:d2:cc:60 brd ff:ff:ff:ff:ff:ff
到目前为止,这两个新建的网络接口都位于宿主机上,属于global(或者称为default)的network namespace。
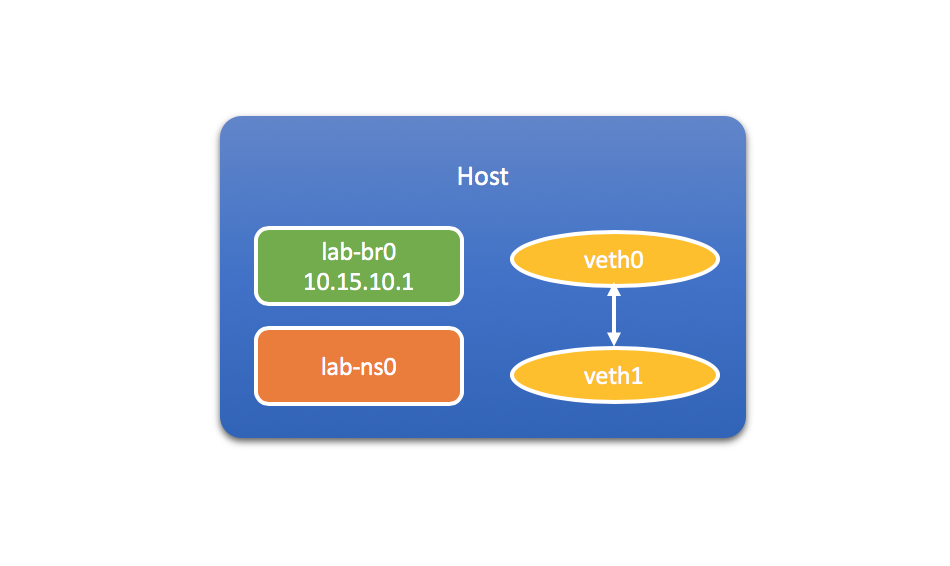
接下来,让我们把其中一端veth1连接到lab-ns0。相当于把veth1“移入”容器对应的network namespace里。作为对比,我们可以在开始移动之前,查看一下lab-ns0目前的网络设备:
$ ip netns exec lab-ns0 ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/ipip 0.0.0.0 brd 0.0.0.0
3: ip6tnl0@NONE: <NOARP> mtu 1452 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/tunnel6 :: brd ::
然后执行如下命令,把veth1移到lab-ns0里:
$ ip link set veth1 netns lab-ns0
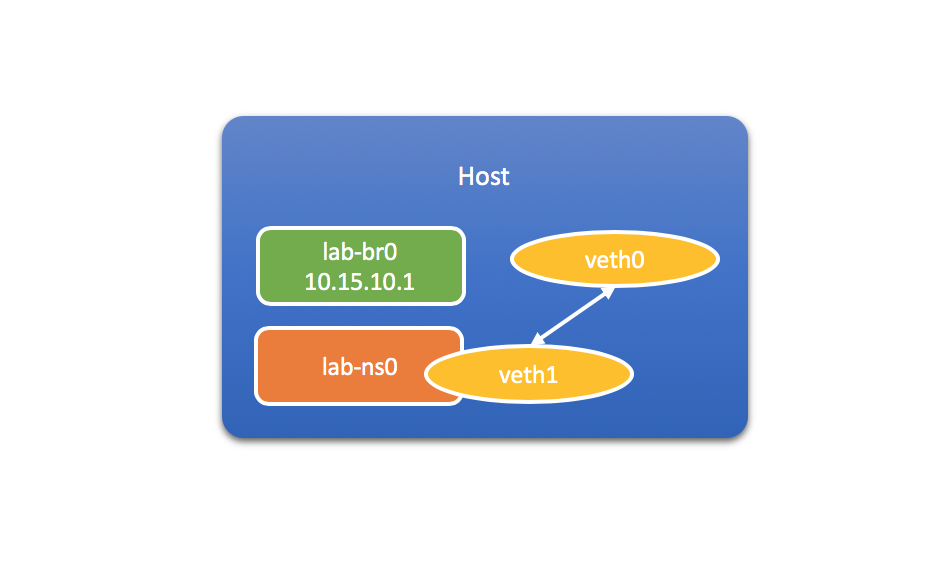
这个时候再查看lab-ns0里的网络设备:
$ ip netns exec lab-ns0 ip link list
... ...
10: veth1@if11: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 62:a1:e7:5c:20:29 brd ff:ff:ff:ff:ff:ff link-netnsid 0
就会发现,和原来相比lab-ns0里多了一个新的网络接口veth1。而且,根据后缀@if11可知,它应该对应于宿主机上序号为11的网络接口。再次在宿主机上执行ip link list:
$ ip link list
... ...
11: veth0@if10: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 22:ad:bb:d2:cc:60 brd ff:ff:ff:ff:ff:ff link-netns lab-ns0
... ...
可以看到veth0前面的序号正是11。而且,原来出现在输出结果里的veth1这时已经消失不见了,原因就是由于我们把它挪到了lab-ns0里。
如果这个时候,我们再把位于lab-ns0里的veth1重新命名为eth0,那就和前面busybox1, busybox2容器里的veth接口看上去一摸一样了:
$ ip netns exec lab-ns0 ip link set veth1 name eth0
$ ip netns exec lab-ns0 ip link list
... ...
10: eth0@if11: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 62:a1:e7:5c:20:29 brd ff:ff:ff:ff:ff:ff link-netnsid 0
接下来,让我们为lab-ns0里的eth0设置IP地址:
$ ip netns exec lab-ns0 ip addr add 10.15.10.2/24 dev eth0
通过ip addr show命令查看eth0,可以验证IP地址是否设置成功:
$ ip netns exec lab-ns0 ip addr show eth0
10: eth0@if11: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 62:a1:e7:5c:20:29 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.15.10.2/24 scope global eth0
valid_lft forever preferred_lft forever
现在,让我们把veth pair的另一端,也就是veth0,连接到lab-br0网桥,或者说“移入”lab-br0,从而实现lab-ns0和宿主机之间的网络连通:
$ brctl addif lab-br0 veth0
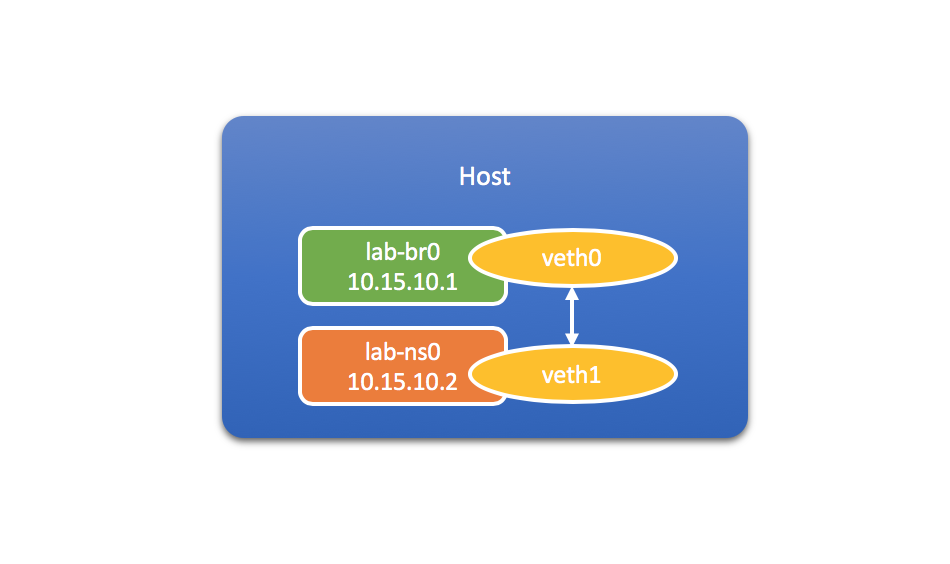
这个时候执行brctl show:
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024277d8e553 no vethe657f66
veth617de44
lab-br0 8000.22adbbd2cc60 no veth0
对照之前的输出结果可以看到,这个时候在lab-br0的intnerfaces字段下出现了veth0,这表明veth0已经成功连接到lab-br0了。
如果这个时候我们在lab-ns0里执行ip route list命令查看静态路由规则:
$ ip netns exec lab-ns0 ip route list
10.15.10.0/24 dev eth0 proto kernel scope link src 10.15.10.2 linkdown
会看到这里唯一的一条路由规则指明了,所有从IP地址为10.15.10.2过来的数据包,都将被路由到10.15.10.0/24这一网段。对照前面我们知道,10.15.10.2对应的就是网络接口veth1,也就是lab-ns0里后来被我们重命名为eth0的那个接口。而10.15.10.0/24则是我们在为lab-br0指定IP地址时所定义的网段。
再来看一下宿主机上的静态路由规则:
$ ip route list
default via 172.20.0.1 dev eth0
10.15.10.0/24 dev lab-br0 proto kernel scope link src 10.15.10.1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.20.0.0/16 dev eth0 proto kernel scope link src 172.20.0.2
其中,dev lab-br0所在行对应的路由规则表明了,通过IP地址10.15.10.1过来的数据包,也会被路由到10.15.10.0/24这一网段,而10.15.10.1就是我们为lab-br0网桥指定的IP地址。
通过对路由规则的分析,我们可以得出结论:数据包在经过lab-ns0的eth0,以及宿主机上的lab-br0时,最终都会被路由到同一网段10.15.10.0/24,因此它们彼此之间应该是可以互相连通的。接下来,我们就来验证这个结论。
验证网络连通性
可以在宿主机和network namespace之间尝试用ping命令验证网络的连通性。不过在这之前,我们还需要把veth pair的两端分别启动起来。首先是宿主机一端的veth0:
$ ip link set dev veth0 up
然后是lab-ns0里的eth0:
$ ip netns exec lab-ns0 ip link set dev eth0 up
# 此处会生成路由规则
最后还需要把lab-ns0里的loopback接口启动起来:
$ ip netns exec lab-ns0 ip link set dev lo up
然后,我们就可以执行ping命令了。比如,在宿主机上试着ping一下lab-ns0里的eth0:
$ ping 10.15.10.2 -c 3
PING 10.15.10.2 (10.15.10.2): 56 data bytes
64 bytes from 10.15.10.2: seq=0 ttl=64 time=0.121 ms
64 bytes from 10.15.10.2: seq=1 ttl=64 time=0.163 ms
64 bytes from 10.15.10.2: seq=2 ttl=64 time=0.164 ms
--- 10.15.10.2 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.121/0.149/0.164 ms
或者从lab-ns0里试着ping一下宿主机上的lab-br0:
$ ip netns exec lab-ns0 ping 10.15.10.1 -c 3
PING 10.15.10.1 (10.15.10.1): 56 data bytes
64 bytes from 10.15.10.1: seq=0 ttl=64 time=0.109 ms
64 bytes from 10.15.10.1: seq=1 ttl=64 time=0.117 ms
64 bytes from 10.15.10.1: seq=2 ttl=64 time=0.167 ms
--- 10.15.10.1 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.109/0.131/0.167 ms
或者从lab-ns0里试着ping一下eth0:
$ ip netns exec lab-ns0 ping 10.15.10.2 -c 3
PING 10.15.10.2 (10.15.10.2): 56 data bytes
64 bytes from 10.15.10.2: seq=0 ttl=64 time=0.106 ms
64 bytes from 10.15.10.2: seq=1 ttl=64 time=0.129 ms
64 bytes from 10.15.10.2: seq=2 ttl=64 time=0.117 ms
--- 10.15.10.2 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.106/0.117/0.129 ms
除此以外,如果我们重复上面的步骤,再新建一个network namespace,比如叫lab-ns1:
$ ip netns list
lab-ns1 (id: 4)
lab-ns0 (id: 3)
并且为它也配好位于同一网段的veth pair,IP地址为10.15.10.3:
$ ip netns exec lab-ns1 ip addr show eth0
12: eth0@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 72:0d:b2:5f:89:a3 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.15.10.3/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::700d:b2ff:fe5f:89a3/64 scope link
valid_lft forever preferred_lft forever
相应的路由规则也会把经过它的数据包路由到10.15.10.0/24网段:
$ ip netns exec lab-ns1 ip route list
10.15.10.0/24 dev eth0 proto kernel scope link src 10.15.10.3
这个时候,如果我们从其中一个network namespace,尝试ping另一个:
$ ip netns exec lab-ns0 ping 10.15.10.3 -c 3
PING 10.15.10.3 (10.15.10.3): 56 data bytes
64 bytes from 10.15.10.3: seq=0 ttl=64 time=0.271 ms
64 bytes from 10.15.10.3: seq=1 ttl=64 time=0.181 ms
64 bytes from 10.15.10.3: seq=2 ttl=64 time=0.637 ms
--- 10.15.10.3 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.181/0.363/0.637 ms
结果发现也是能ping通的。这说明,多个network namespace只要被路由到同一网段(也就是加入到同一网络),那它们之间就可以实现互通。在Docker里,多个容器通过加入同一bridge网络实现互通,就是这个原理!
留下评论
您的电子邮箱地址并不会被展示。请填写标记为必须的字段。 *