
注: 本文采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。
利用tcpdump和iptables这两个超级“武器”,让我们一起来揭开Service网络背后的神秘面纱吧!
在Kubernetes网络篇——Service网络(上)一文里我们学会了Service的定义,部署和访问,并了解了Kubernetes的DNS服务。本文,我们将借助tcpdump和iptables这两个工具,对Service网络的数据包和iptables规则进行分析,从而进一步理解Service网络的工作原理。
使用tcpdump
假设我们从位于节点kube-node-2上的lab-sleeper容器内部向位于节点kube-node-1上的lab-web容器发起一个HTTP请求,Kubernetes在网络层面到底做了哪些事情呢?
为此,我们在节点kube-node-2安装了tcpdump工具。利用它,我们可以对流经该节点网络接口的数据包进行分析:
$ apt-get update
$ apt-get install tcpdump
先来看一下lab-sleeper容器在宿主机一端的veth接口,观察一下流经这个接口的数据包。为此,我们需要在kube-node-2上找到lab-sleeper容器的veth接口。先看一下lab-sleeper容器内部的eth0接口:
$ kubectl exec -it lab-sleeper-7ff95f64d7-6p7bh ip link
... ...
5: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ae:6c:5c:6d:d5:83 brd ff:ff:ff:ff:ff:ff link-netnsid 0
可以看到,@符号后面跟的序号为11,这说明和它相对应的宿主机一端的veth接口序号为11。再来看一下宿主机上的网络接口:
$ ip link
... ...
11: veth707db50e@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master dind0 state UP mode DEFAULT group default
link/ether 76:d5:ba:61:7c:7c brd ff:ff:ff:ff:ff:ff link-netnsid 1
... ...
这里,序号为11的网络接口为veth707db50e,这就是我们要监听的接口。而且,veth707db50e的@符号后面跟的序号为5,这说明容器端和它相对应的veth接口,其序号也应该是5。这和我们前面查看容器内网络接口的输出结果是一致的。
下面我们开始监控veth707db50e接口,在kube-node-2上执行如下命令:
$ tcpdump -i veth707db50e -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth707db50e, link-type EN10MB (Ethernet), capture size 262144 bytes
这里,参数-i用于指定监控的网络接口,即:veth707db50e;参数-nn用于告诉tcpdump,在输出结果里以数字方式显示IP和端口。
然后,我们从另一个终端窗口登录到master节点,在lab-sleeper容器里执行curl命令,向test-svc发送请求:
$ kubectl exec -it lab-sleeper-7ff95f64d7-6p7bh curl http://test-svc
这个时候,我们会在tcpdump所在的终端窗口看到类似下面这样的输出:
08:14:47.120669 IP 10.244.3.5.34361 > 10.96.0.10.53: 90+ A? test-svc.default.svc.cluster.local. (52)
08:14:47.121229 IP 10.96.0.10.53 > 10.244.3.5.34361: 90*- 1/0/0 A 10.107.169.79 (102)
08:14:47.121373 IP 10.244.3.5.34361 > 10.96.0.10.53: 8557+ AAAA? test-svc.default.svc.cluster.local. (52)
08:14:47.121834 IP 10.96.0.10.53 > 10.244.3.5.34361: 8557*- 0/1/0 (145)
08:14:47.124539 IP 10.244.3.5.41408 > 10.107.169.79.80: Flags [S], seq 3978858651, win 29200, options [mss 1460,sackOK,TS val 217014590 ecr 0,nop,wscale 7], length 0
08:14:47.124719 IP 10.107.169.79.80 > 10.244.3.5.41408: Flags [S.], seq 3710748951, ack 3978858652, win 28960, options [mss 1460,sackOK,TS val 217014590 ecr 217014590,nop,wscale 7], length 0
08:14:47.124775 IP 10.244.3.5.41408 > 10.107.169.79.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 217014590 ecr 217014590], length 0
08:14:47.124960 IP 10.244.3.5.41408 > 10.107.169.79.80: Flags [P.], seq 1:73, ack 1, win 229, options [nop,nop,TS val 217014590 ecr 217014590], length 72: HTTP: GET / HTTP/1.1
08:14:47.125037 IP 10.107.169.79.80 > 10.244.3.5.41408: Flags [.], ack 73, win 227, options [nop,nop,TS val 217014590 ecr 217014590], length 0
08:14:47.125445 IP 10.107.169.79.80 > 10.244.3.5.41408: Flags [P.], seq 1:239, ack 73, win 227, options [nop,nop,TS val 217014590 ecr 217014590], length 238: HTTP: HTTP/1.1 200 OK
08:14:47.125490 IP 10.244.3.5.41408 > 10.107.169.79.80: Flags [.], ack 239, win 237, options [nop,nop,TS val 217014590 ecr 217014590], length 0
08:14:47.127164 IP 10.244.3.5.41408 > 10.107.169.79.80: Flags [F.], seq 73, ack 851, win 247, options [nop,nop,TS val 217014590 ecr 217014590], length 0
这里我们可以看到,前4行显示,容器(IP地址为10.244.3.5)是在和kube-dns(IP地址为10.96.0.10)进行通信;从第5行开始,就在和test-svc(IP地址为10.107.169.79)进行真正的HTTP通信了。因此,对容器来说,所有发送出去的数据包,其目标地址都是Service的IP地址;相应地,所有返回的数据包,其源地址也都是Service的IP地址。在容器看来,它始终都是在和Service通信,并没有和“躲”在Service背后的Pod有直接交流。
接下来,我们再往上一层,看一看流经宿主机网卡eth0的数据包,所有从当前节点发往其他节点的数据包都会经过这个网络接口:
$ tcpdump -i eth0 -nn port 53 or port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
这里,我们给tcpdump加了过滤条件。这样可以让我们真正关心的数据包不会淹没在大量无关的输出结果里。通过参数port,我们告诉tcpdump只监听端口53和80。前者是DNS服务的端口;后者是HTTP服务的端口,即lab-web,也就是躲在test-svc背后我们要访问的目标Pod。
再次从lab-sleeper容器里通过curl命令发起对test-svc的请求,我们得到了类似下面这样的输出:
10:22:17.990253 IP 10.192.0.4.39982 > 10.244.2.2.53: 19731+ A? test-svc.default.svc.cluster.local. (52)
10:22:17.991031 IP 10.192.0.4.39982 > 10.244.2.2.53: 2856+ AAAA? test-svc.default.svc.cluster.local. (52)
10:22:17.992065 IP 10.244.2.2.53 > 10.192.0.4.39982: 2856*- 0/1/0 (145)
10:22:17.993465 IP 10.244.2.2.53 > 10.192.0.4.39982: 19731*- 1/0/0 A 10.107.169.79 (102)
10:22:18.001390 IP 10.192.0.4.38010 > 10.244.2.4.80: Flags [S], seq 519874336, win 29200, options [mss 1460,sackOK,TS val 217780596 ecr 0,nop,wscale 7], length 0
10:22:18.001516 IP 10.244.2.4.80 > 10.192.0.4.38010: Flags [S.], seq 17221823, ack 519874337, win 28960, options [mss 1460,sackOK,TS val 217780596 ecr 217780596,nop,wscale 7], length 0
10:22:18.001574 IP 10.192.0.4.38010 > 10.244.2.4.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 217780596 ecr 217780596], length 0
10:22:18.002088 IP 10.192.0.4.38010 > 10.244.2.4.80: Flags [P.], seq 1:73, ack 1, win 229, options [nop,nop,TS val 217780596 ecr 217780596], length 72: HTTP: GET / HTTP/1.1
10:22:18.002196 IP 10.244.2.4.80 > 10.192.0.4.38010: Flags [.], ack 73, win 227, options [nop,nop,TS val 217780596 ecr 217780596], length 0
10:22:18.002311 IP 10.244.2.4.80 > 10.192.0.4.38010: Flags [P.], seq 1:239, ack 73, win 227, options [nop,nop,TS val 217780596 ecr 217780596], length 238: HTTP: HTTP/1.1 200 OK
10:22:18.002335 IP 10.192.0.4.38010 > 10.244.2.4.80: Flags [.], ack 239, win 237, options [nop,nop,TS val 217780596 ecr 217780596], length 0
10:22:18.002373 IP 10.244.2.4.80 > 10.192.0.4.38010: Flags [P.], seq 239:851, ack 73, win 227, options [nop,nop,TS val 217780596 ecr 217780596], length 612: HTTP
10:22:18.002399 IP 10.192.0.4.38010 > 10.244.2.4.80: Flags [.], ack 851, win 247, options [nop,nop,TS val 217780596 ecr 217780596], length 0
10:22:18.009205 IP 10.192.0.4.38010 > 10.244.2.4.80: Flags [F.], seq 73, ack 851, win 247, options [nop,nop,TS val 217780597 ecr 217780596], length 0
10:22:18.009392 IP 10.244.2.4.80 > 10.192.0.4.38010: Flags [F.], seq 851, ack 74, win 227, options [nop,nop,TS val 217780597 ecr 217780597], length 0
10:22:18.009422 IP 10.192.0.4.38010 > 10.244.2.4.80: Flags [.], ack 852, win 247, options [nop,nop,TS val 217780597 ecr 217780597], length 0
可以看到,和之前一样,前面4行仍然是容器和DNS服务之间的通信;从第5行开始,则是容器和HTTP服务之间的通信。不同的地方在于,从容器里发送出来的数据包在经过eth0的时候,源地址已经变成了节点的IP。在我们的例子里,也就是kube-node-2的IP地址10.192.0.4。相应地,所有eth0接收到的数据包,其目标地址也变成了10.192.0.4。
另外,在和DNS服务交互的数据包里,DNS服务的IP地址也变成了真正提供服务的Pod——coredns的地址了。如果查一下kube-system下的Pod就会发现,coredns的IP地址就是10.244.2.2:
$ kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-fb8b8dccf-nggnj 1/1 Running 0 7h47m 10.244.2.2 kube-node-1 <none> <none>
... ...
最后,原来test-svc的IP地址,也被替换成了真正提供HTTP服务的Pod地址,即:位于节点kube-node-1上的lab-web,IP地址为10.244.2.4。
结合两次tcpdump的结果,我们可以用下面这张图来做一个小结。
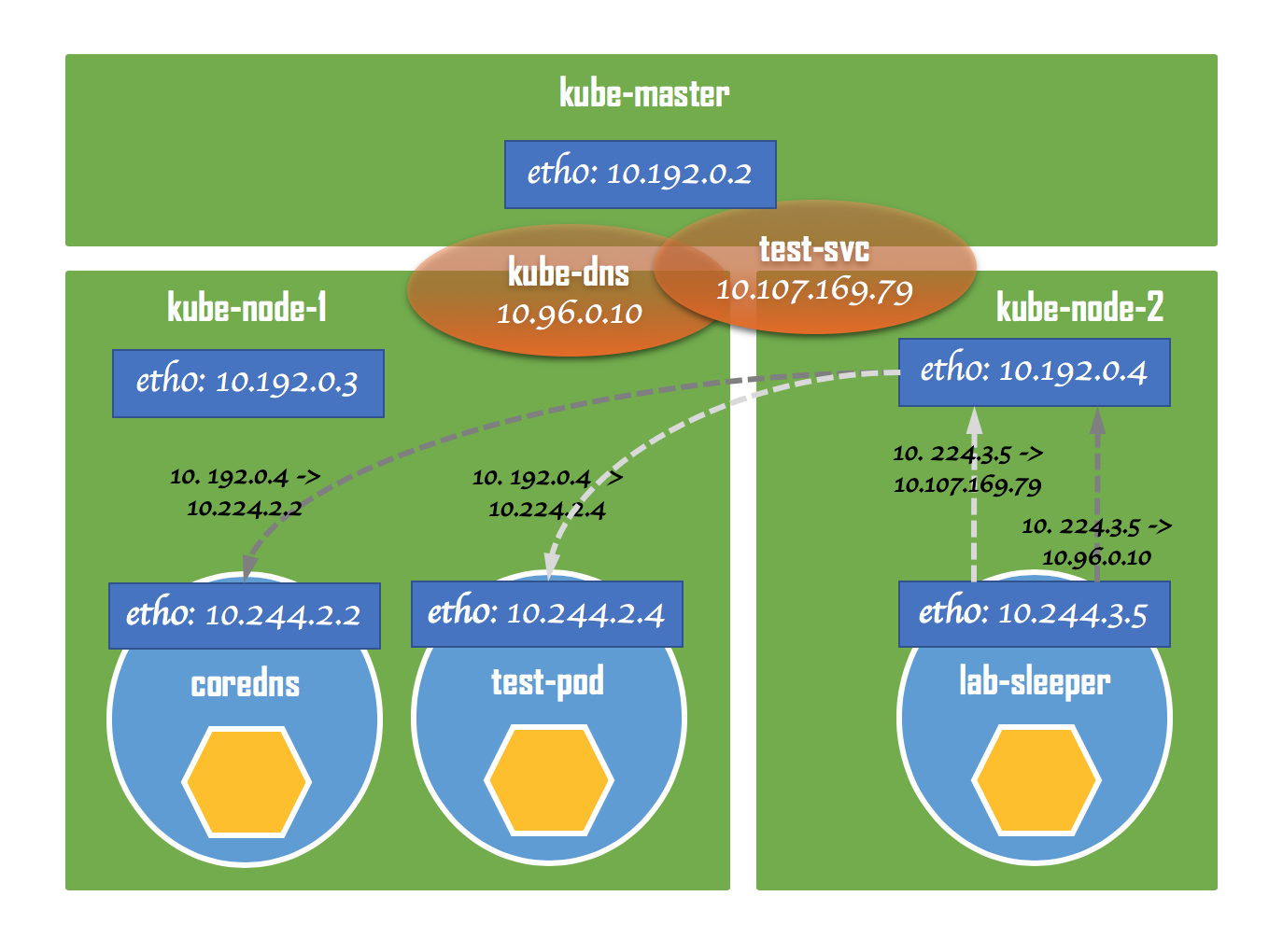
从lab-sleeper发出的数据包,其目标地址总是Service的虚拟IP,包括kube-dns和我们的test-svc。但当经过主机的eth0以后,目标地址就会被替换成真正提供服务的后端Pod,即coredns和test-pod,而源地址则会被替换成主机的IP。同样地,对于返回的数据包,其源地址和目标地址又会被逆向还原。这样,在lab-sleeper看来,它始终是在和Service进行通信,而没有和Service所管理的后端Pod存在任何直接的交流。
使用iptables
通过对流经eth0的数据包进行监控,我们看到了Service很好的屏蔽了它所管理的后端Pod。但是,Kubernetes是怎么做到这一点的呢?这就需要借助另一个工具iptables了。

在Kubernetes里,Service的网络实际上是通过iptables规则来实现的。因此,理解Service网络的工作原理,还应该分析一下iptables的规则。
这些规则是通过kube-proxy在Kubernetes集群的各个节点上自动生成的。每当有新的Service变动来自master节点,kube-proxy都会收到事件通知,并更新iptables规则。并且,集群当中的每个节点上都有一份相同的iptables配置,这样就保证了,当有Pod在任何节点上想访问某个Service的时候,都能正确地路由到目标地址。
下面,我们在lab-sleeper所在的kube-node-2上执行iptables-save命令,将会得到了类似下面这样的输出:
$ iptables-save
⎢ ...
① -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
⎢ ...
⑨ -A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
⎢ ...
④ -A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
⑩ -A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
⎢ ...
⎢ -A KUBE-SEP-CLAGU7VMF4VCXE4X -s 10.244.2.2/32 -j KUBE-MARK-MASQ
⎢ -A KUBE-SEP-CLAGU7VMF4VCXE4X -p tcp -m tcp -j DNAT --to-destination 10.244.2.2:9153
⑦ -A KUBE-SEP-E2HMOHPUOGTHZJEP -s 10.244.2.4/32 -j KUBE-MARK-MASQ
⑧ -A KUBE-SEP-E2HMOHPUOGTHZJEP -p tcp -m tcp -j DNAT --to-destination 10.244.2.4:80
⎢ -A KUBE-SEP-H7FN6LU3RSH6CC2T -s 10.244.2.2/32 -j KUBE-MARK-MASQ
⎢ -A KUBE-SEP-H7FN6LU3RSH6CC2T -p tcp -m tcp -j DNAT --to-destination 10.244.2.2:53
⎢ -A KUBE-SEP-TCIZBYBD3WWXNWF5 -s 10.244.2.2/32 -j KUBE-MARK-MASQ
⎢ -A KUBE-SEP-TCIZBYBD3WWXNWF5 -p udp -m udp -j DNAT --to-destination 10.244.2.2:53
⎢ ...
② -A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-MARK-MASQ
⎢ -A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
⎢ -A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-MARK-MASQ
⎢ -A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4
⎢ -A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:metrics cluster IP" -m tcp --dport 9153 -j KUBE-MARK-MASQ
⎢ -A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:metrics cluster IP" -m tcp --dport 9153 -j KUBE-SVC-JD5MR3NA4I4DYORP
③ -A KUBE-SERVICES -d 10.107.169.79/32 -p tcp -m comment --comment "default/test-svc: cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
⑤ -A KUBE-SERVICES -d 10.107.169.79/32 -p tcp -m comment --comment "default/test-svc: cluster IP" -m tcp --dport 80 -j KUBE-SVC-W3OX4ZP4Y24AQZNW
⎢ ...
⎢ -A KUBE-SVC-ERIFXISQEP7F7OF4 -j KUBE-SEP-H7FN6LU3RSH6CC2T
⎢ -A KUBE-SVC-JD5MR3NA4I4DYORP -j KUBE-SEP-CLAGU7VMF4VCXE4X
⎢ -A KUBE-SVC-TCOU7JCQXEZGVUNU -j KUBE-SEP-TCIZBYBD3WWXNWF5
⑥ -A KUBE-SVC-W3OX4ZP4Y24AQZNW -j KUBE-SEP-E2HMOHPUOGTHZJEP
通过tcpdump的执行我们已经知道了,Kubernetes实际上是对数据包的源地址和目标地址做了网络地址转换(Network Addtress Translation,即NAT),我们只需要查看NAT表的PREROUTING链和POSTROUTING链就可以了。所以这里对iptables-save的输出结果做了点处理。首先,我们略去了无关的规则,只保留了关心的部分;其次,为了方便后面解释说明,我们在某些规则前面加上了序号。
- 当数据包从lab-sleeper发出,并经过eth0的时候,首先会命中行①处的PREROUTING规则。因为没有任何额外的匹配条件,所以这条规则总是会命中;
- 紧接着,根据行①的规则,它会跳转到KUBE-SERVICES链,即:从行②处开始的一系列KUBE-SERVICES规则。这里前几条规则都是和DNS服务相关的,因为原理大同小异,所以我们就略过了。假设目前这个数据包就是发往lab-web的,那么最后它将匹配行③处的KUBE-SERVICES;
- 行③处的规则代表了目标地址为
10.107.169.79,端口号为80的数据包,它将跳转到行④处的KUBE-MARK-MASQ规则; - 行④处的KUBE-MARK-MASQ实际代表了IP地址伪装(MASQUERADE),准确地说是对源地址进行伪装。至于怎么伪装,我们等一下再说。因为目前还在PREROUTING链上,所以这里并不是进行真正地伪装,而是利用
--set-xmark设置了一个特殊的标记0x4000/0x4000,表示这个数据包是需要地址伪装的。后面,我们会看POSTROUTING链是如何根据这个标记对数据包进行IP地址伪装的; - 由于行④处的KUBE-MARK-MASQ规则后面跟了一个非终止目标(non-terminating target,即:不像ACCEPT,DROP,REJECT那样,会终止整个
iptables规则链的解析),所以它会重新跳回行③处,沿着KUBE-SERVICES链继续往下走到行⑤处; - 行⑤处的KUBE-SERVICES同样匹配目标地址为
10.107.169.79,端口号为80的数据包,它将跳到行⑥处的KUBE-SVC-W3OX4ZP4Y24AQZNW规则,然后再到行⑦处开始的KUBE-SEP-E2HMOHPUOGTHZJEP链上; - 从行⑦处开始的两条KUBE-SEP-E2HMOHPUOGTHZJEP规则里,只有第二条规则满足我们的数据包,即行⑧处。这里,我们会进行一次针对目标地址的网络地址转换(DNAT),把目标地址替换成
10.244.2.4:80,即真正在test-svc后端提供HTTP服务的test-pod。这也是为什么我们在eth0上监控到发送出去的数据包里,目标地址被替换成test-pod的IP的原因; - 最后,从行⑨处开始我们进入POSTROUTING链,然后跳转到行⑩处的KUBE-POSTROUTING规则;
- 行⑩处的KUBE-POSTROUTING规则会对数据包进行判断,如果发现它有
0x4000/0x4000标记,就会跳到MASQUERADE规则,也就是真正对数据包的源地址进行IP地址伪装。具体来说,就是自动把数据包里的源地址替换成主机网卡eth0的IP地址,即:10.192.0.4。这也是为什么我们在eth0上监控到发送出去的数据包里,源地址被替换成主机IP的原因;
最后,数据包在经过网络地址转换以后,被发送到了test-pod,当有数据包从test-pod返回的时候,操作系统(实际上是位于Linux kernel层的netfilter)会进行相应的逆向转换,把地址又重新替换成原来的值。所以,在lab-sleeper看来,它是一直在和test-svc打交道。
多Pod间的负载均衡
下面我们来看一下,Service后端连接多个Pod的情况。看一下在多个Pod的情况下,Service是如何做负载均衡的。我们先利用kubectl scale命令,把test-pod的个数从当前的1个扩展到3个:
$ kubectl scale --replicas=3 deployment/test-pod
deployment.extensions/test-pod scaled
然后通过kubectl get pods命令确认所有test-pod都已经成功启动:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
lab-sleeper-7ff95f64d7-6p7bh 1/1 Running 0 23h 10.244.3.5 kube-node-2 <none> <none>
test-pod-9dd7d4f7b-56znc 1/1 Running 0 27h 10.244.2.4 kube-node-1 <none> <none>
test-pod-9dd7d4f7b-7jtcv 1/1 Running 0 15s 10.244.3.6 kube-node-2 <none> <none>
test-pod-9dd7d4f7b-qdmvd 1/1 Running 0 15s 10.244.2.6 kube-node-1 <none> <none>
最后,再次执行iptables-save命令,并把输出结果和扩展Pod之前的结果进行对比,我们发现下面几条iptables规则是新加的:
⎢ -A KUBE-SEP-EEXR7SABLH35O4XP -s 10.244.3.6/32 -j KUBE-MARK-MASQ
⎢ -A KUBE-SEP-EEXR7SABLH35O4XP -p tcp -m tcp -j DNAT --to-destination 10.244.3.6:80
⎢ -A KUBE-SEP-WFXGQBTRL5EC2R2Y -s 10.244.2.6/32 -j KUBE-MARK-MASQ
⎢ -A KUBE-SEP-WFXGQBTRL5EC2R2Y -p tcp -m tcp -j DNAT --to-destination 10.244.2.6:80
① -A KUBE-SVC-W3OX4ZP4Y24AQZNW -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-E2HMOHPUOGTHZJEP
② -A KUBE-SVC-W3OX4ZP4Y24AQZNW -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-WFXGQBTRL5EC2R2Y
③ -A KUBE-SVC-W3OX4ZP4Y24AQZNW -j KUBE-SEP-EEXR7SABLH35O4XP
其中,前4条规则是test-pod扩展以后,针对新生成的两个Pod进行网络地址转换用的。因为原理相同,所以这里我们就略过了。下面我们重点关注一下后3条规则。
我们看到,行①和行②处的规则使用了statistic模块,这是对进入网卡的数据包进行概率计算用的,即:通过概率计算的结果来决定是否匹配规则。下面我们具体来看一下:
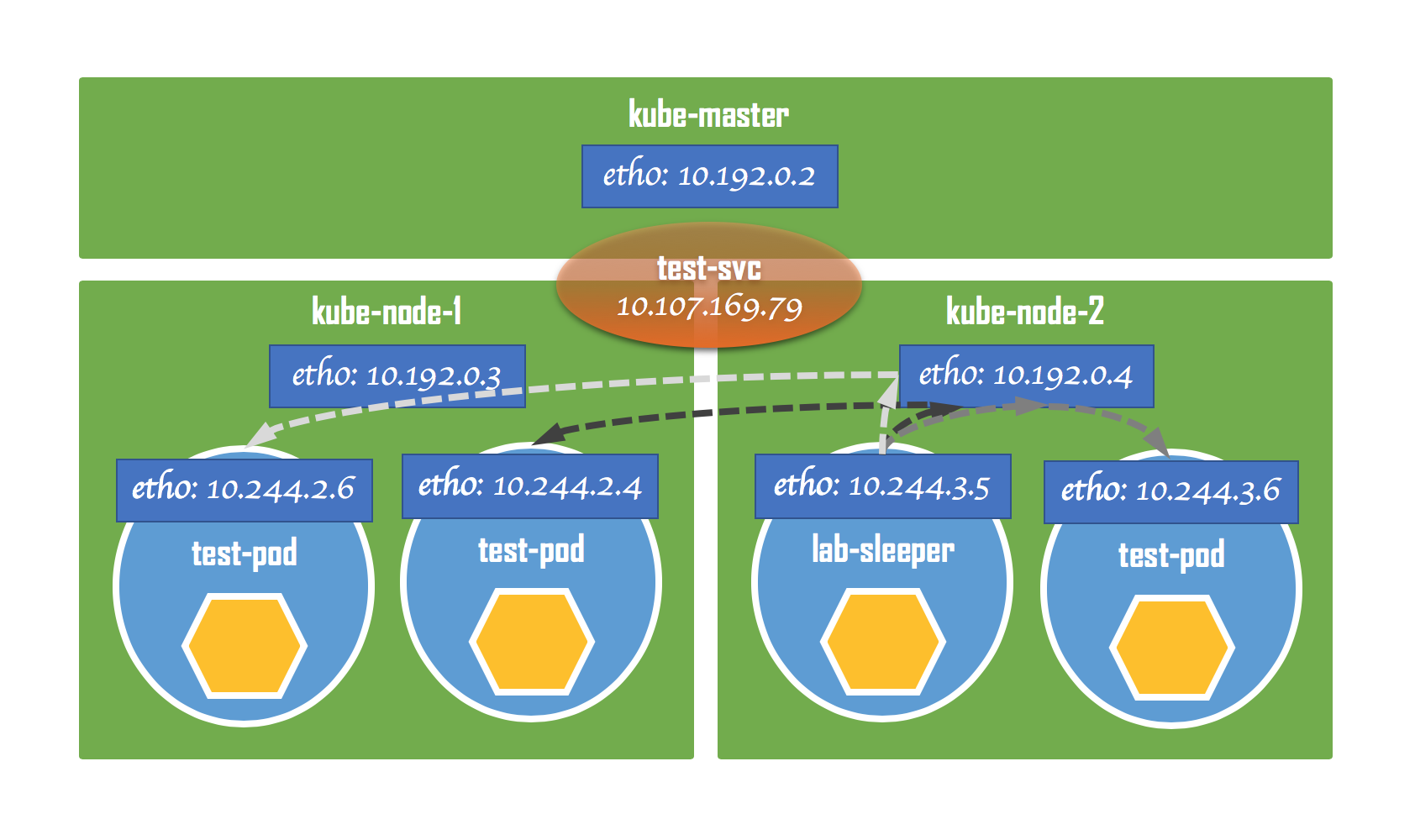
- 假设数据包现在到达行①处,由于行①设定的概率值为
0.33332999982,所以在所有数据包里,将会有1/3的数据包匹配这条规则,而剩下2/3的数据包则会到达行②。和当前规则相匹配的数据包,它的目标地址会被替换成10.244.2.4,对应test-pod-9dd7d4f7b-56znc; - 由于行②设定的概率值为
0.50000000000,所以在余下的数据包里,将会有1/2的数据包匹配这条规则,而剩下1/2的数据包则会到达行③。这里,2/3的一半就是1/3。和当前规则相匹配的数据包,它的目标地址会被替换成10.244.2.6,对应test-pod-9dd7d4f7b-qdmvd; - 最后还剩下1/3的数据包到达了行③,由于行③并没有设定概率值,所以相当于概率值为
1,即:所有剩下的数据包都将匹配这条规则。匹配这条规则的数据包,其目标地址会被替换成10.244.3.6,对应test-pod-9dd7d4f7b-7jtcv;
经过上述处理以后,发往test-svc的数据包最终被平均分布到了3个test-pod上,从而实现了负载均衡。
这种负载均衡有一个要求,那就是和Service相连的每一个后端Pod,提供的应该都是相同的服务。而且,因为经过负载均衡处理以后,发往同一Service的前后两次请求无法保证会到达同一Pod,所以这些Pod应该都是无状态的,也就是不依赖于任何客户端状态。
主机访问的iptables规则
最后补充一点,大家在Kubernetes网络篇——Service网络(上)一文里已经看到了,我们不仅可以从Pod内部访问集群里的某个Service,还可以直接在主机(即:集群节点)上对Service进行访问,这同样是通过设置iptables规则做到的。
如果我们回顾前面iptables-save的输出结果,应该会注意到里面有一条类型为OUTPUT的规则:
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
根据iptables的文档,如果数据包是直接由本地应用产生的,那么OUTPUT链就会被触发。在集群节点的主机上直接发起curl命令访问test-svc,就属于这种情况。因此,就会匹配这条OUTPUT规则,并跳转到KUBE-SERVICES链上。而对照前面的分析,从这条规则往后,数据包在iptables规则链上的走向就和来自Pod内部的普通数据包一摸一样了。不过,由于主机没有配置使用kube-dns,所以我们只能用IP地址访问Service,而无法通过名称来访问。
小结
通过前面的实验我们可以看到,在Kubernetes的集群里,Pod和节点之所以能够访问到Service,完全是因为iptables规则在起作用。
跑在Pod里的容器利用路由规则,把数据包成功送到宿主机以后,就把“接力棒”交给了宿主机上的iptables规则。正是因为这些规则的作用,数据包才能被成功发送的目的地。而这个目的地很可能是跨集群节点的。
所以,Service的网络在本质上只是当前主机上的一堆iptables规则,并不是一个网络设备。
留下评论
您的电子邮箱地址并不会被展示。请填写标记为必须的字段。 *